前回、
「discord.pyでテキスト読み上げるdiscordbotの作成」
https://blog.comorichico.com/83
やりましたが今度はYouTubeのコメントを読み上げます!
環境:
Windows10 Home
まずはPython3.10をインストールします。
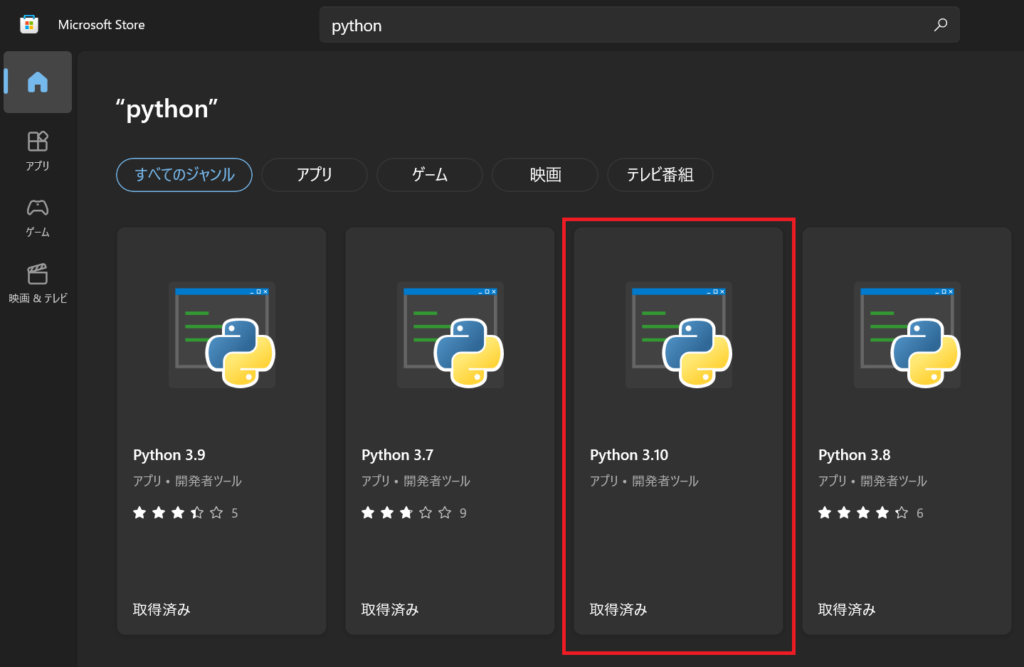
Microsoft Store を使う場合↓
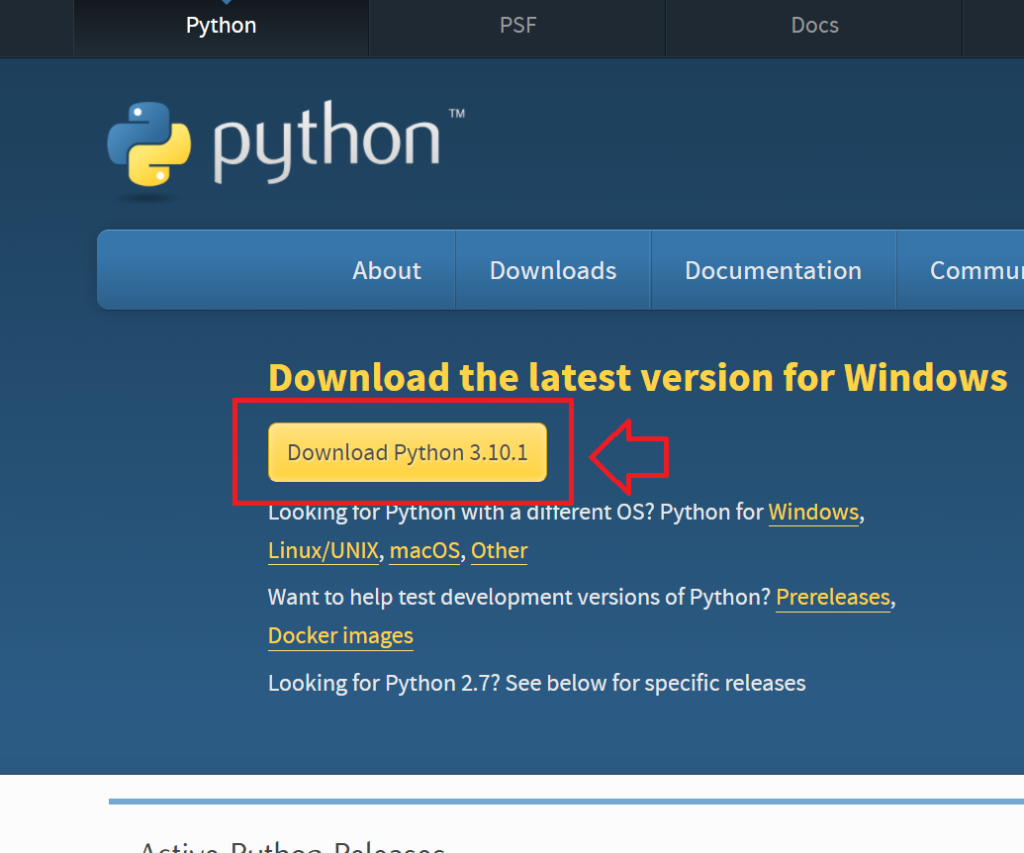
Python公式からダウンロードする場合↓
( Microsoft Store からインストールできた人は読み飛ばしてください)
https://www.python.org/downloads/
上記のサイトを開いて、
ダウンロードしたpython-3.10.1-amd64.exeをダブルクリックします。
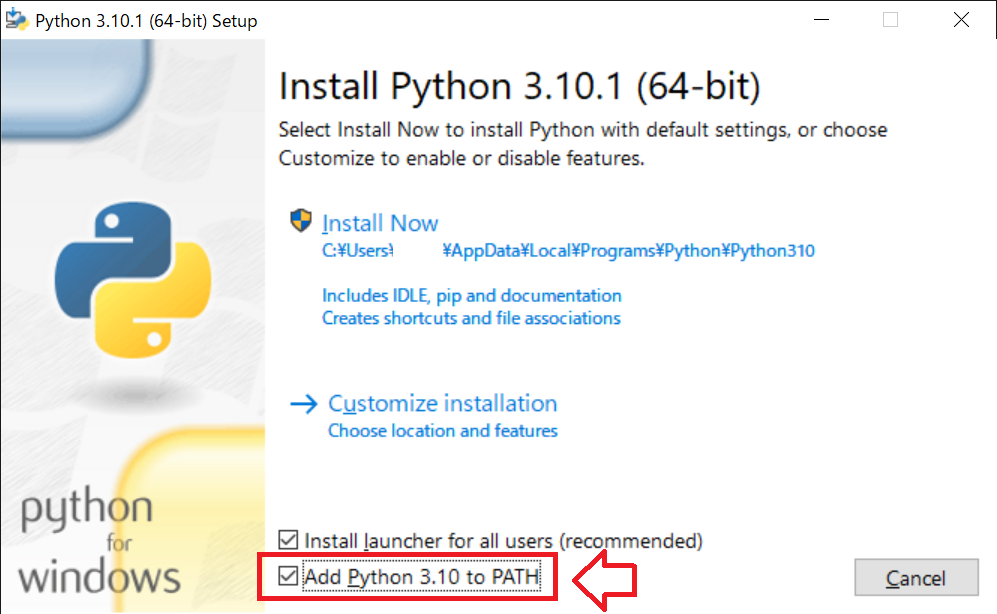
外れていますがここはチェック入れます!
チェック入れたら上にある「Install Now」を押します。
次にVOICEVOXをインストールします。
https://voicevox.hiroshiba.jp/
上記のサイトを開いて右にあるダウンロードのボタンを押します。
今回ダウンロードできたのはVOICEVOX.Web.Setup.0.9.3.exeでした。
ダブルクリックして起動してインストールします。
インストールが終わったら
C:\Users\[user名]\AppData\Local\Programs\VOICEVOX\
ここのフォルダにrun.exeがあるのでそれを起動します。
起動したらタスクバーにピン留めしておくと次回から起動が楽だと思います。
([user名]は自分の環境に置き換えてください。)
Windowsの検索バーにcmdと入れてコマンドプロンプトを起動します。
pip install pytchat
pip install requests
pip install simpleaudio
これを1行ずつ打ってインストールします。
import pytchat
import time
import asyncio
import json
import requests
import wave
import simpleaudio
async def generate_wav_file(text, speaker, filepath):
audio_query = requests.post(f'http://127.0.0.1:50021/audio_query?text={text}&speaker={speaker}')
headers = {'Content-Type': 'application/json',}
synthesis = requests.post(
f'http://127.0.0.1:50021/synthesis?speaker={speaker}',
headers=headers,
data=json.dumps(audio_query.json())
)
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(synthesis.content)
wf.close()
async def main_loop():
# PytchatCoreオブジェクトの取得
livechat = pytchat.create(video_id = "WCDTV3JggZE")# video_idはhttps://....watch?v=より後ろの
speaker = 8 # 8は春日部つむぎのノーマル
filepath = 'audio.wav'
print("コメント取得を開始します。")
while livechat.is_alive():
# チャットデータの取得
chatdata = livechat.get()
for c in chatdata.items:
print(f"{c.datetime} {c.author.name} {c.message} {c.amountString}")
await generate_wav_file(c.author.name + "、" + c.message, speaker, filepath)
wav_obj = simpleaudio.WaveObject.from_wave_file(filepath)
play_obj = wav_obj.play()
play_obj.wait_done()
time.sleep(5)
asyncio.run(main_loop())
上記のコードをテキストエディタにコピー&ペーストして保存します。普段使っているテキストエディタがない人はWindowsのメモ帳でもいいです。
場所はどこでも良いですがここでは
C:\Users\[user名]\youtube-text-to-speech.py
に保存しておきました。
コード内のvideo_id = “WCDTV3JggZE”のところを配信する動画のURLのidに置き換えます。
例ですが、URLが
https://www.youtube.com/watch?v=WCDTV3JggZE
だった場合は
video_id = “WCDTV3JggZE”
のようにします。
speaker = 8 のところは変えるとボイスを変更できます。
0:四国めたん、あまあま
1:ずんだもん、あまあま
2:四国めたん、ノーマル
3:ずんだもん、ノーマル
4:四国めたん、セクシー
5:ずんだもん、セクシー
6:四国めたん、ツンツン
7:ずんだもん、ツンツン
8:春日部つむぎ、ノーマル
9:波音リツ、ノーマル
現在のVOICEVOXのバージョンではこのようになっているみたいです。ボイスは今後増えるみたいです。

コマンドプロンプトを起動して、
python youtube-text-to-speech.py
でプログラムの起動ができます。あとは配信にコメントすると読み上げてくれます。
これで音が鳴るので配信する時はOBSのデスクトップ音声で取り込むと良いと思います。
以上です!説明で間違ってるところとか分からないところがあったらこの記事のコメント欄かTwitterで連絡ください。
おつかれさまでした!またねー